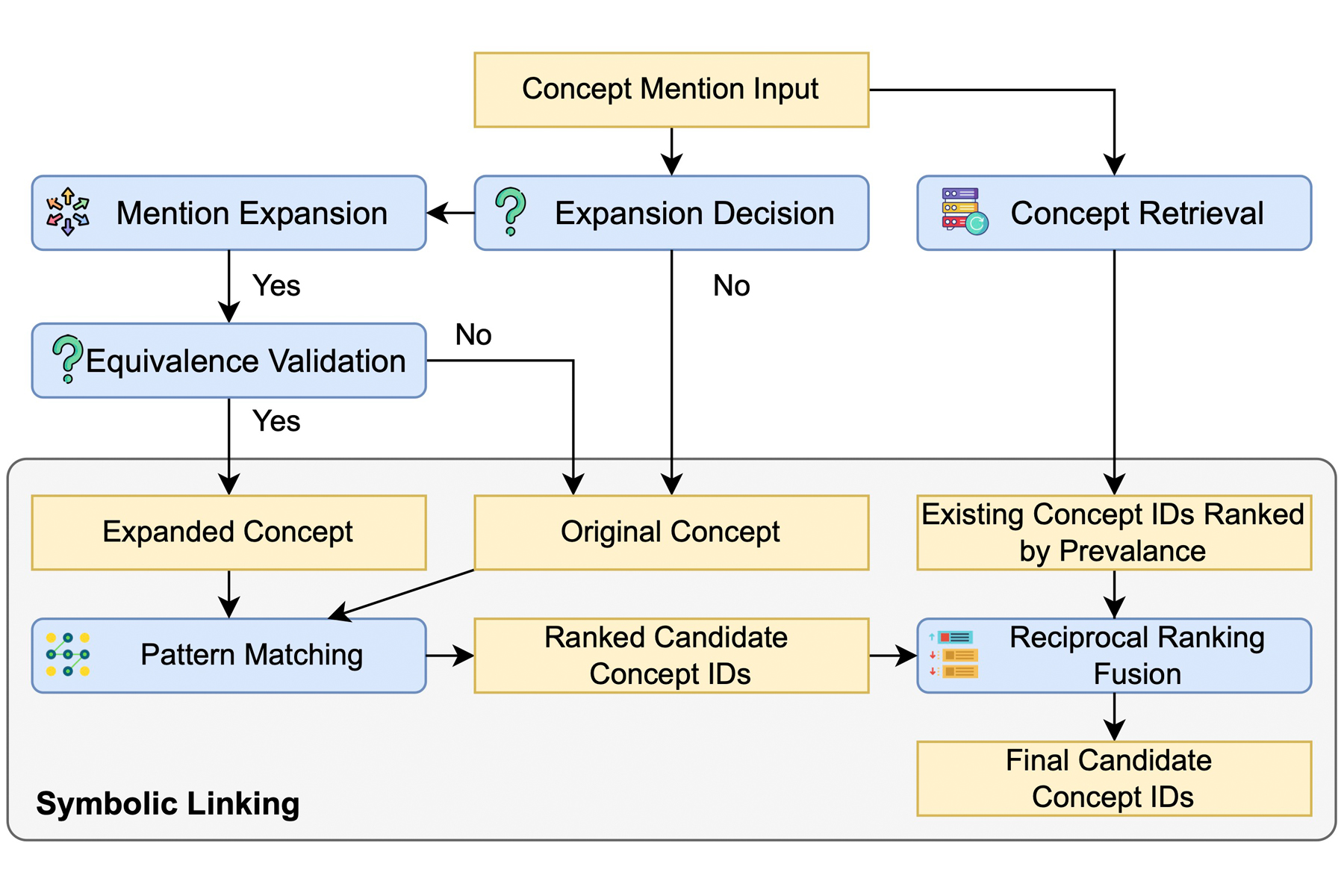
To solve this, researchers at Columbia University developed a neural-symbolic AI agent system called Medical Concept Mapping (MCM). As detailed in a recent study in npj Digital Medicine, MCM uses a language model to clarify ambiguous biomedical mentions in context, checks whether the clarification preserves the original meaning, and then applies symbolic matching to link the mention to standardized UMLS concepts. This neural-symbolic approach improved concept-mapping accuracy across benchmark datasets, especially for rare and abbreviated terms.
“Large language models are useful for interpreting ambiguous biomedical language, but we should not rely on them alone to assign standardized medical concepts,” said lead author Gongbo Zhang, Associate Research Scientist in the Department of Biomedical Informatics. “In MCM, we use the language model to clarify a mention in context, then apply symbolic matching and validation to ensure the final mapping remains grounded in established biomedical terminology. This neural-symbolic workflow makes concept normalization more accurate, interpretable, and reliable, especially for rare or abbreviated terms.”
One Abbreviation, Multiple Possibilities
“RA” is a commonly used abbreviation for rheumatoid arthritis, so it would be natural for a doctor to use that in clinical notes. If that patient also developed cardiovascular issues in the right atrium, or perhaps the renal artery, then the same abbreviation could be used within those clinical notes.
Ensuring that ‘RA’ connects to the correct concept—whether it’s an autoimmune condition or a specific blood vessel—requires more than just a dictionary. It requires a system that can use surrounding context to clarify the term, verify that the clarification preserves the original meaning, and then ground the result in standardized biomedical terminology.
While rule-based systems can match exact patterns efficiently, they lack the scalability to handle thousands of variations and can break down over simple typos. Learning-based methods (including LLMs) are better at inferring meaning through context clues but struggle with accuracy when encountering medical concepts not included in their original training data. MCM instead functions as an agentic system that follows a specific set of steps to ensure higher levels of accuracy.
A Logical Approach to Identification
The stakes of accuracy are high. The abbreviation “CJS” can represent an array of vastly different disorders, ranging from a genetic condition (Curry-Jones Syndrome) to an endocrine one (Culler-Jones Syndrome) to a degenerative brain disease (Creutzfeldt-Jakob Disease). When tested against these complex cases, traditional rule-based and AI systems often failed, with some guessing entirely unrelated conditions like prostate cancer.
MCM correctly identified CJS as Curry-Jones syndrome through a stepwise workflow: it determined that the abbreviation required clarification, used the surrounding context to expand the mention, checked semantic equivalence, and then linked it to the appropriate UMLS concept.
This checks-and-balances process allowed MCM to significantly outperform established tools like ScispaCy and KrissBERT. Most notably, MCM thrived in the “long-tail” of data—the underrepresented concepts that standard AI often misses. On zero-shot abbreviated mentions, MCM achieved substantially higher Recall@1 than the baselines; for example, on MedMentions, it reached 36.3 compared with 11.5 for KrissBERT.

“The broader lesson is that healthcare AI does not have to be a black box,” Zhang said. “By designing systems that expose intermediate steps, such as whether a term needs clarification, how it was expanded, and how it was linked, we can make AI outputs easier to inspect, verify, and trust.”
Reliability at the Forefront
As AI tools continue to transform healthcare research, the focus must shift from pure speed to absolute reliability. MCM provides a blueprint for this future by proving that researchers do not have to choose between the flexibility of AI and the rigor of medical logic. By connecting LLMs to verified medical truths, we can move toward a future where AI acts as a transparent and trustworthy partner in clinical discovery.
Zhang views this system as a piece of “fundamental infrastructure” that is essential for diverse areas of research. In a global research environment where every patient’s data is valuable, MCM ensures that critical medical insights don’t get lost in translation. By creating a standard system that is computable and comparable across organizations, researchers can trust the data to tell the full story of human health.
More Information
The study, A neural-symbolic AI agent system for biomedical concept mapping, was published in Nature Digital Medicine on April 4, 2026.
The full list of authors includes Yilu Fang, Fangyi Chen, Casey Ta, George Hripcsak, Patrick Ryan, Yifan Peng, and Chunhua Weng.
This work was supported by the National Center for Advancing Translational Sciences (NCATS) of the National Institutes of Health (NIH) under grant numbers UL1TR001873 and UL1TR002384. The research was also funded by NIH grants R01LM014344 and R01LM014573, and by the National Library of Medicine grant T15LM007079.