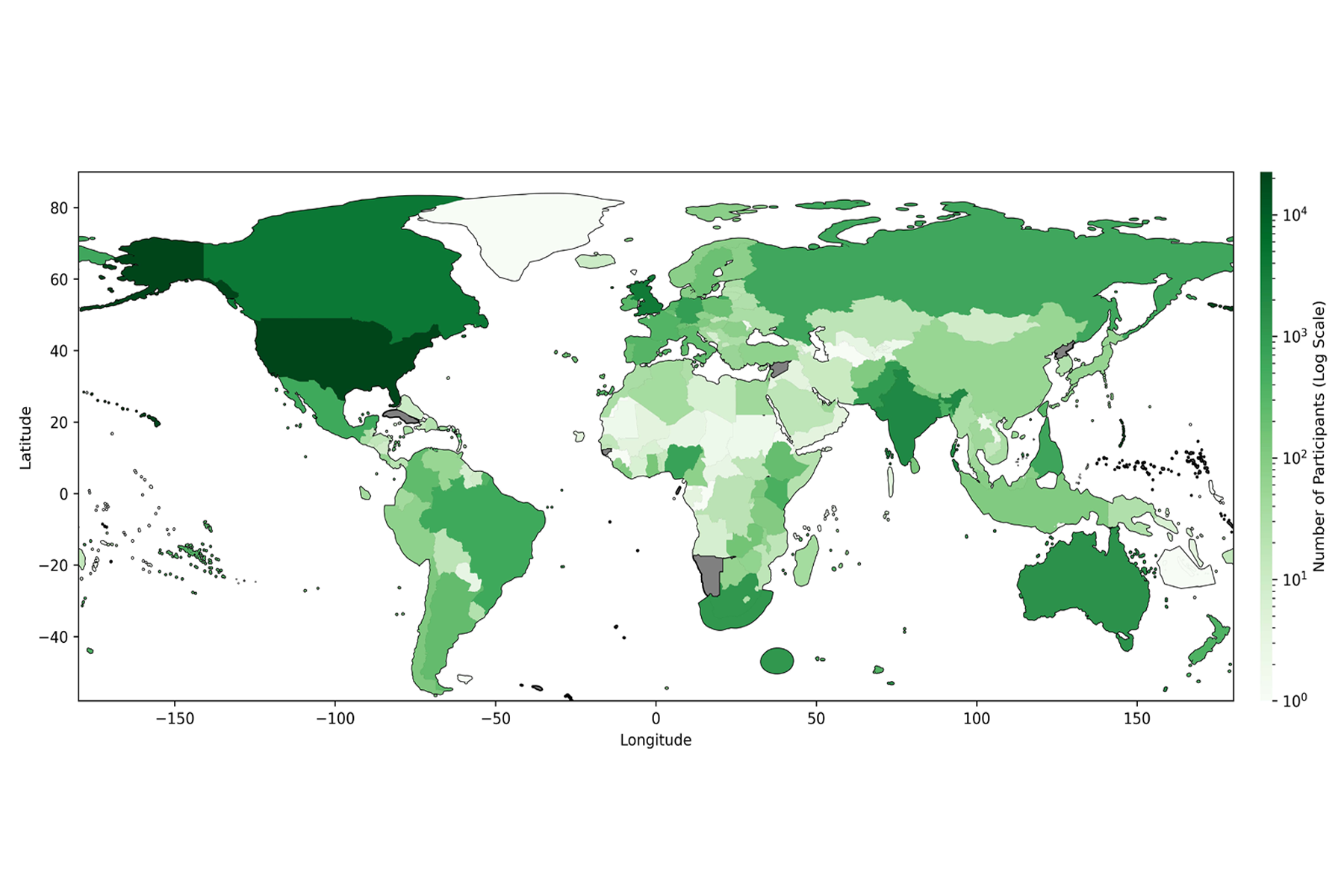
Gürsoy Named Irving Scholar for Research on Overcoming Privacy Challenges in Machine Learning for Healthcare
Collaboration Within Interactive, Mobile, Wearable and Ubiquitous Technologies Research Opens Doors for Significant Breakthroughs
Jason Adelman, Director of New Center for Patient Safety Science, Focuses on Advances & Innovations to Improve Safety
PhD Profile: Amanda Moy Focused On Establishing A Methodological Roadmap For Measuring Documentation Burden
Columbia Hosted 2023 Machine Learning for Healthcare Conference; DBMI Faculty, Trainees Served In Several Roles
PhD Profile: Anna Ostropolets Uses Knowledge Engineering, Observational Research To Aid Those Who Need It Most
Hripcsak Accepts Collen Award of Excellence; DBMI Trainees Honored, Lead Justice Informatics Session At AMIA
Using Digitized Data To Create Decision Support Tools, Find Life-Saving Signals Is Focus Within Park Lab
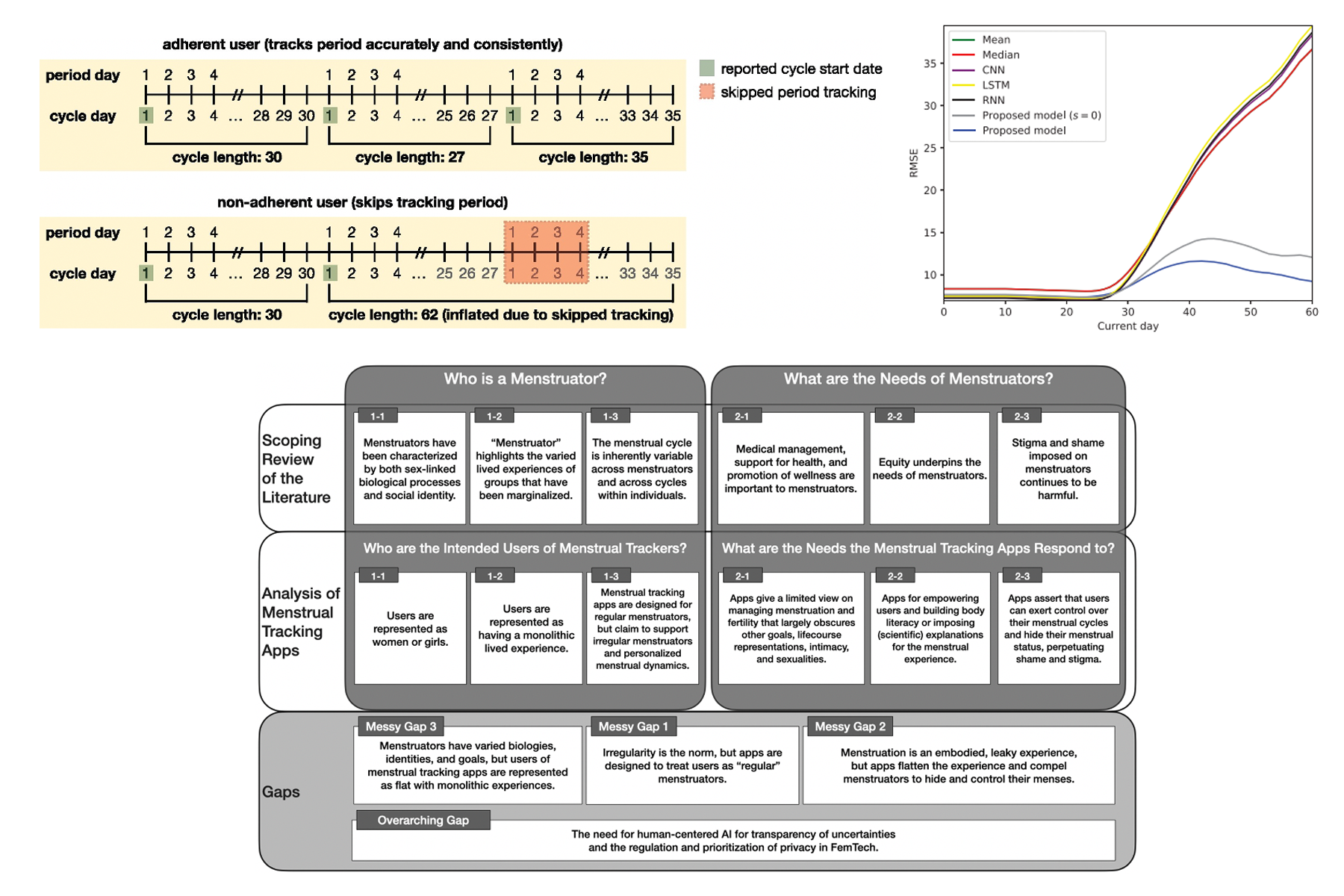
Informatics Provides Opportunities To Generate Reliable Knowledge, Reduce Stigma For A Global Community Of Menstruators
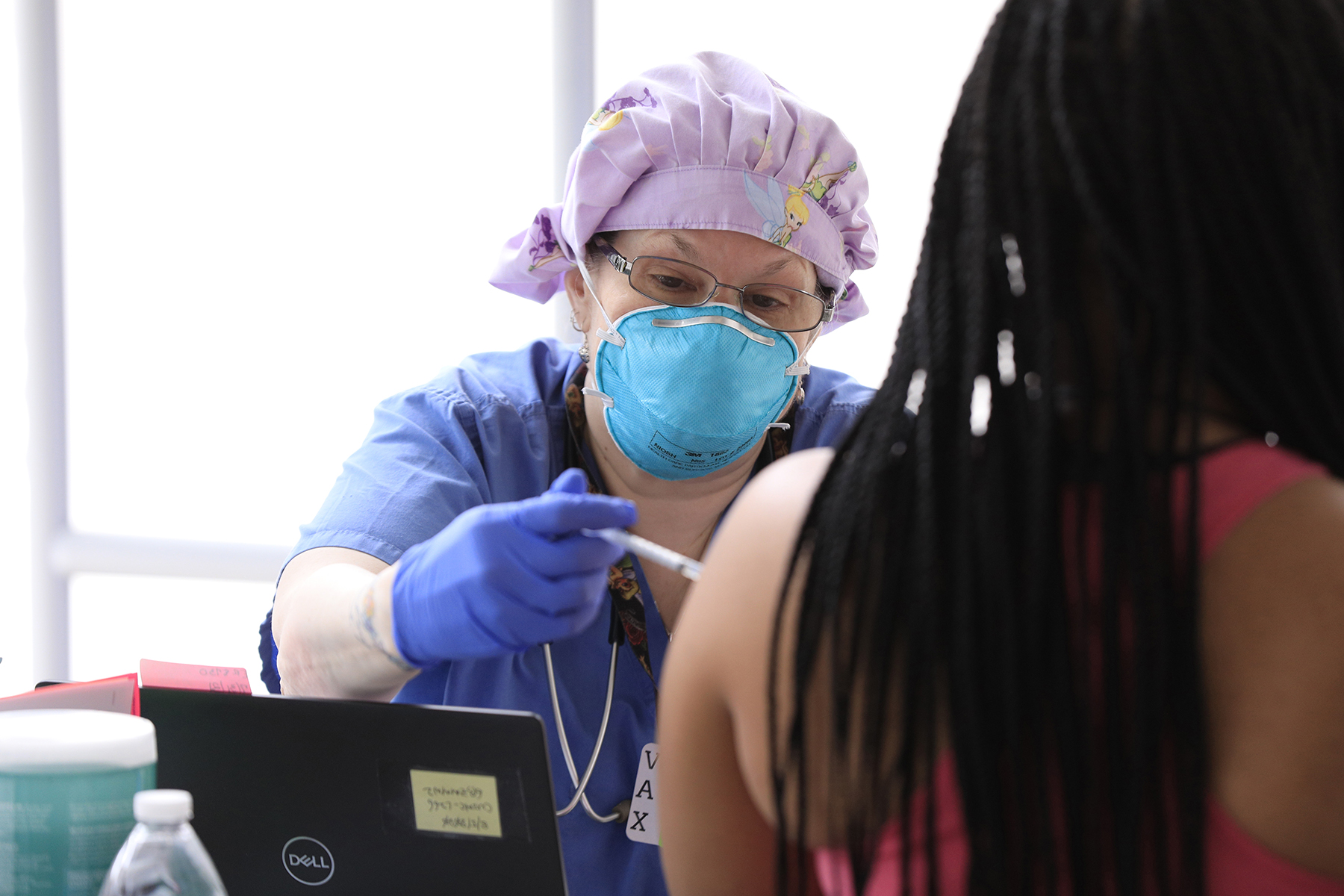
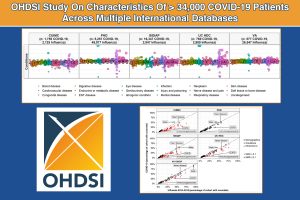
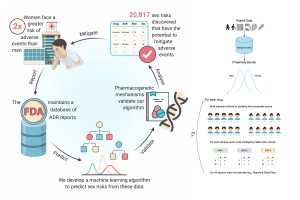
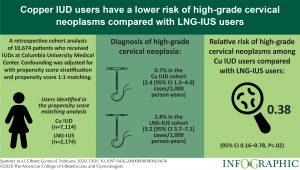
Largest, Most Extensive Study Of Adverse Events Background Rates Can Inform COVID Vaccines Safety Monitoring Efforts
Rimma Perotte PhD ’16, Casey Overby Taylor PostDoc ’13, Featured In Biomedical Informatics Training Series
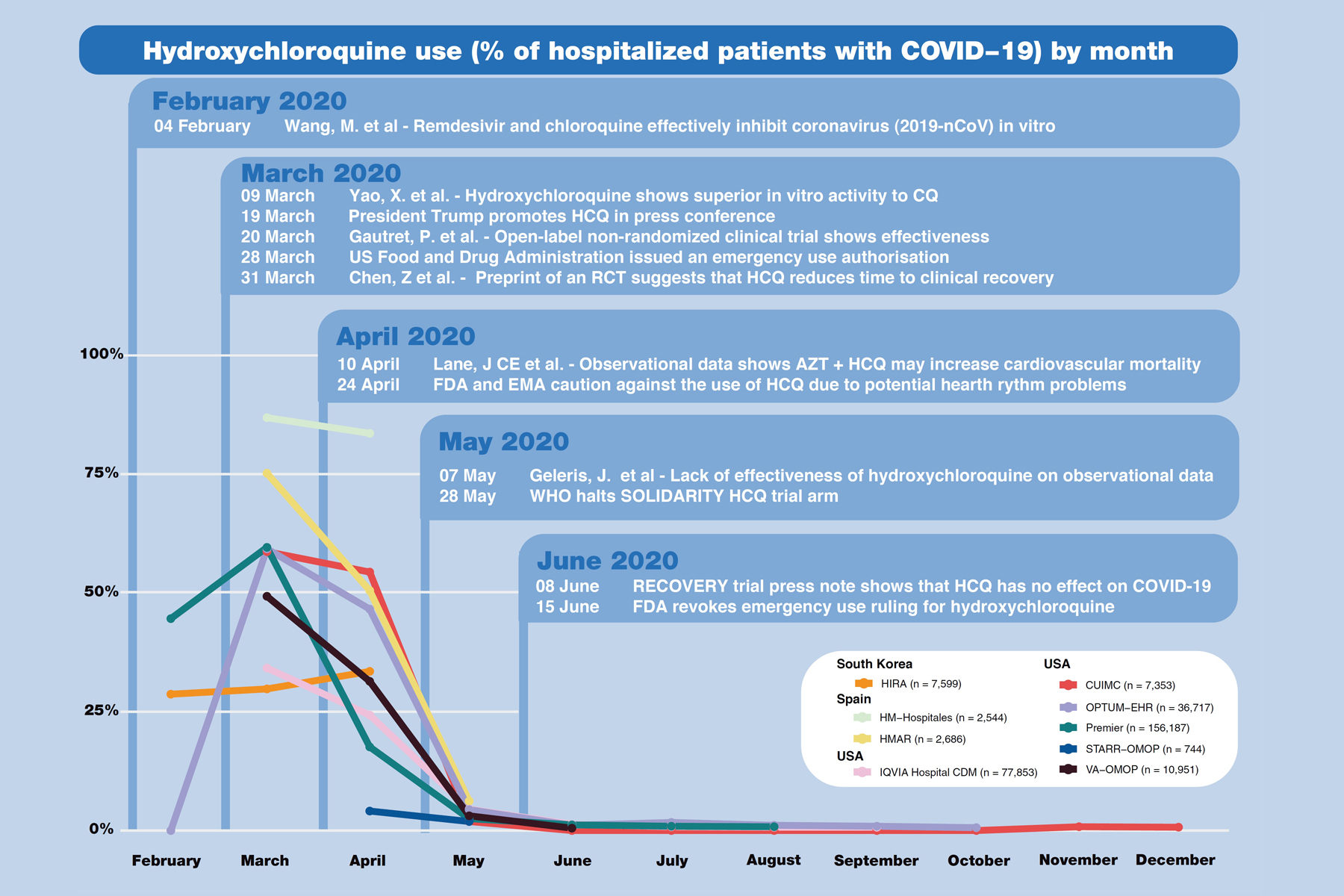
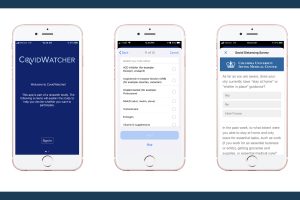
Insufficient Data, Misleading Recommendations Led To Early Heterogeneity In Global COVID-19 Patient Management
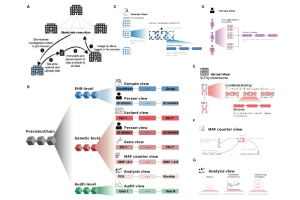
HL7 Int’l, OHDSI to Collaborate to Provide Single CDM for Sharing Information in Clinical Care & Observational Research
Interventional Studies Provide Decision-Support Tools To Support Cancer Management, Prevention Decisions
DBMI Announces Special Seminar Series: Toward Diversity, Equity, and Inclusion in Informatics, Health Care, and Society
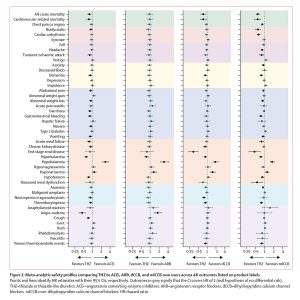
World’s Largest Study on ACE Inhibitors, ARBs Shows No Increased Patient Risk of COVID-19 Diagnosis, Complications
OHDSI Awarded $10 Million FDA Contract to Support Safety/Effectiveness Surveillance of Vaccines, Other Biological Products
OHDSI Kicks Off International Collaborative to Generate Real-World Evidence on COVID-19 with Virtual Study-a-thon
Within Emerging Field Of Computational Biology, Yufeng Shen Seeks Discovery Of Novel Genetic Variants
From Informatics To Social Research, Dr. Mollie McKillop Took All-Encompassing Approach To Study Endometriosis
Non-Traditional Thinking Guides Nicholas Tatonetti, Ph.D., To Important Advancements In Health, Healthcare
Adelman Study Evaluates Safety of Restricting vs Allowing Multiple Records Open in an Electronic Health Record